



















- Pythonでスクレイピングツールを作成する手順
- Pythonでスクレイピングするサンプルコード
Webサービスから必要な情報を自動で取得するスクレイピングツールは便利です。
スクレイピングツールは、いろいろな言語で開発できますが、中でもPythonはライブラリが豊富でスクレイピングツールを簡単に構築することができます。
しかし、初めてスクレイピングツールを構築する場合、どのような手順で作成すればよいかわからない方も多いのではないでしょうか。
そこでこの記事では、Pythonでスクレイピングツールを作成する手順をサンプルコードを交えて解説します。
これからスクレイピングツールを開発する際に役立つ内容となっています。
ぜひ最後までご覧ください。
Pythonでのスクレイピングツール開発用の環境構築
Pythonでスクレイピングツールを開発するための環境を構築していきます。
Pythonのプロジェクト仮想環境
今回のスクレイピングツール用の仮想環境(プロジェクト)を作成します。
対象のディレクトリに移動し、以下のコマンドを実行してください。
python -m venv myenv仮想環境作成後、以下のコマンドで仮想環境を有効化しておいてください。
myenv\Scripts\activateSelenium WebDriverのインストール
スクレイピングするためのSeleniumライブラリを仮想環境にインストールします。
仮想環境を有効化した状態で、以下のコマンドを実行してください。
pip install seleniumwebdriver-managerのインストール
スクレイピングにはWebDriverというプログラムが利用するブラウザが必要です。
webdriver-managerは、実行環境のバージョンにあったWebDriverを自動でダウンロードしてくれるライブラリです。
便利なのでインストールしておきます。
pip install webdriver-managerWebDriverは、プログラムを実行させる環境のブラウザ・バージョンにあったモジュールを準備がする必要があります。例えば、Chromeを利用している環境であれば、ChromeのWebDriver、Edgeを利用している環境であれば、EdgeのWebDriverの用意が必要です。
この記事のサンプルでは、Google Chrome用のWebDriverをプログラム内で自動でダウンロードしますが、手動でダウンロードする場合は、実行する環境にインストールされているWebDriverをダウンロードしてください。
ChromeDriverの場合は、こちらからダウンロードできます。バージョンは、実行する環境のブラウザのバージョンと一致するものを選択してください。
取得対象のWebサービス
今回は「Yahoo!Japan」のサイトからタイトルと検索用のテキストボックスの情報を取得します。
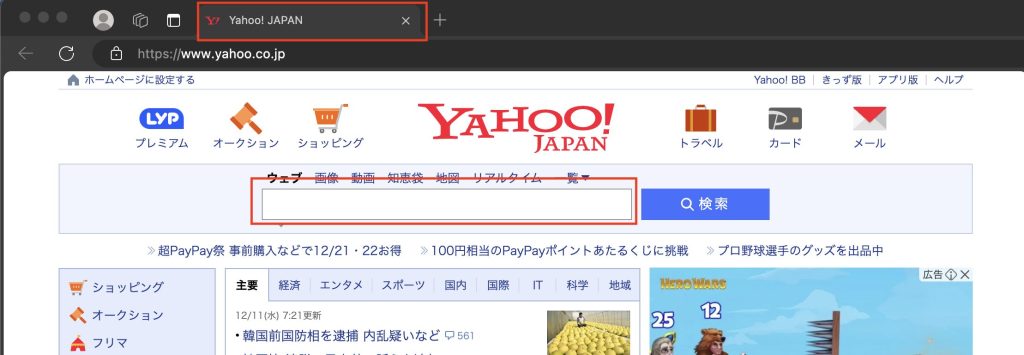
検索用のテキストボックスは一見、何も値がありませんがソースを見ると以下の様になっています。今回は「aria-label」の値を取得します。

サンプルコード
from webdriver_manager.chrome import ChromeDriverManager
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.service import Service
# WebDriverを自動的に管理
service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service)
# driver = webdriver.Chrome(ChromeDriverManager().install())
# スクレイピング対象のURL ここではyahooをサンプルに指定
url = 'https://www.yahoo.co.jp/'
# ウェブページを開く
driver.get(url)
# タイトルを取得
title = driver.title
# タイトルを表示
print(f'Title: {title}')
# ページ内の指定の要素までスクロールし、要素の値を取得
# XPathを使用して<input type="search" aria-label="検索したいキーワードを入力してください">要素を取得
element= driver.find_element(By.XPATH, '//input[@type="search"][@aria-label]')
driver.execute_script('arguments[0].scrollIntoView({behavior: "smooth", block: "center"});', element)
# "aria-label"属性の値を取得
aria_label_value = element.get_attribute('aria-label')
# 取得した値を表示
print(aria_label_value)
# ブラウザを閉じる
driver.quit()
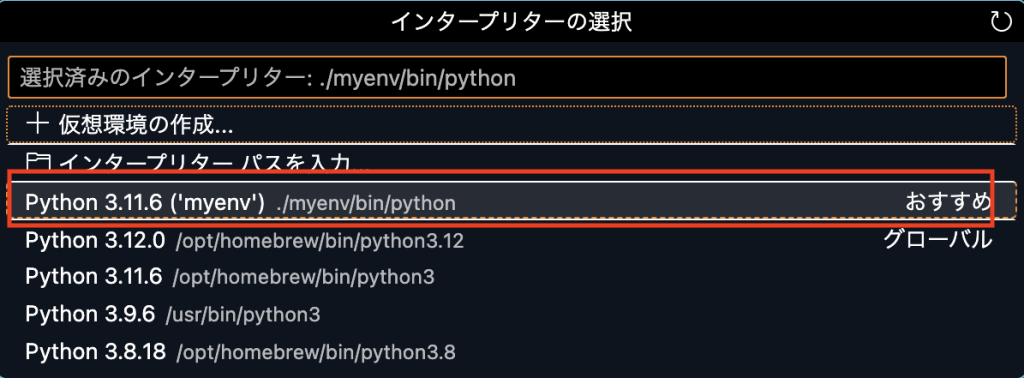
正しくインタープリターが選択されていないので、「Ctrl+Shift+P」を押して、仮想環境のインタープリターを選択してください。
- Step1「Python インタープリターを選択」

- Step2仮想環境のpythonを選択。
サンプルコードの解説
順番にコードを解説していきます。
WebDriverのインポート
from selenium import webdriverSeleniumのWebDriverをプログラム内で使える様にインポートします。
WebDriverのパスを指定
driver_path = '/path/to/chromedriver'WebDriverのパスを設定しています。
スクレイピング対象のWebサービスを指定
url = 'https://www.yahoo.co.jp/'どのWebサービスを対象にするかを指定します。今回はyahooJapanを指定しています。
Webページを開く
driver.get(url)指定したページの情報を取得しています。
Webの内容を取得
title = driver.title取得したページの情報からタイトルを取得しています。
ページ内の指定の要素の値を取得
element= driver.find_element(By.XPATH, '//input[@type="search"][@aria-label]')
driver.execute_script('arguments[0].scrollIntoView({behavior: "smooth", block: "center"});', element)取得したページの中の要素(コントロール)を指定し、値を取得しています。
ページ上でスクロールが表示されている場合など、取得対象の値が隠れていると失敗するので、「driver.execute_script」で対象の要素までスクロールしてから値を取得しています。
ブラウザを閉じる
driver.quit()スクレイピング完了後、WebDriverを終了させています。
スクレイピングサンプルコードの実行結果
サンプルコードを実行すると、ターミナル上に以下のように取得した値が出力されます。

まとめ
- PythonでスクレイピングはSeleniumWebDriverを使う
- webdriver-managerを使うと実行環境にあったWebDriverをダウンロードしてくれて便利
Pythonだとライブラリが豊富なので、簡単にスクレイピングツールが作成できます。
スクレイピングは業務効率化のための便利ツールなどで使いやすい技術です。色々なところで応用が効く技術だと思いますので、この機会にぜひスクレイピングの開発スキルを習得してみてください。
本記事が皆様の参考になれば幸いです。
関連記事:Pythonスクリプトをexe化する!VSCodeでpyinstallerを使う方法


コメント