


















この記事では、AWS Glueを使って分散処理を簡単に実現する方法を紹介します。
- 処理は単純だけど対象データが多くて処理に時間がかかる
- ハードウェアやインスタンスのスペックを上げても性能がでない
- プログラムを見直してもパフォーマンス改善が見込めない
- 簡単に処理時間を向上させる方法を知りたい
単純な処理でも大量のデータを処理する場合、パフォーマンスが出ないことはよくあります。
OSのスペック強化やプログラムのアルゴリズムの見直し、DBのパフォーマンスチューニングを行っても、パフォーマンス改善には限界があります。
このような場合、複数台のパソコンで並列に分散処理を行うことがパフォーマンス向上のために有効です。
しかし、分散処理は並列で処理した結果をまとめる必要があるなど、アルゴリズムが複雑になりがちです。
今回紹介するAWS Glueを利用することで、このような分散処理を簡単に導入できます。
処理の負荷に応じて並列実行させる数も変更できるため、データ量に応じて適切に対応することができます。
この記事では大量のファイルを1ファイルにまとめる処理を例として、AWS Glueの使い方を紹介します。
この記事を読むことで、AWS Glueを利用して分散処理を行う手順がわかります。
実際の開発現場で役立つ内容となってますので、ぜひ最後までご覧ください。
AWS Glueとは
AWSが提供するETLのサービスです。
内部的にApache Sparkを利用し分散処理を簡単に実現することができます。
データソースとして、S3やRDS、DynamoDBなどが利用できます。
データの抽出(Extract)、変換(Transform)、ロード(Load)のこと。
AWS Glueには、大きく以下の機能があります。
ブックマーク
前回処理したデータを覚えておく機能です。
この機能を利用することで、2回目以降の実行では前回処理以降の差分データを処理することができます。
前回実行との差分を処理するためのアルゴリズムを作成する必要はありません。
- ブックマークでの差分処理対象は、追加、変更があったデータが対象です。削除データは対象となりません。、
- ブックマークは処理が正常終了した時のみ有効です。
- ジョブが失敗した場合は新しくブックマークはされません。
クローラー
S3やRDSなど、対象のデータソースを巡回する機能です。この機能を使うことでS3やRDSの内容から自動でメタ情報を抽出することができます。
クローラーの巡回頻度は任意で設定でき、手動で実行することも可能です。
本記事ではこの機能は不要なため、設定はしません。
データカタログ
スキーマのメタ情報を記録しておく機能です。クローラーによって、検知されたデータソースの情報が記録されます。メタ情報の記録先にはDatabaseが利用されます。
こちらもクローラーと同様、本記事では不要なため設定しません。
AWS Glueの料金
AWS Glueはジョブが実行されている時間分、料金がかかります。請求時間は最低10分(または1分)からです。
他のAWSサービスの料金体系と同様に、AWS Glue以外のS3やRDSなどの他のサービスを利用した料金もかかります。
詳細はAWSの公式サイト(AWS Glueの料金)を参照ください。
AWS Glueのジョブの作成方法
AWS Glueのジョブの作成方法を解説します。
事前準備
AWS Glueのスクリプトに設定するIAMロールと、データソースとなるS3のバケットを作成しておきます。
IAMロールの作成
マネジメントコンソールでS3のメニューに移動し、ロールを作成していきます。
「サービスまたはユースケース」に「Glue」を選択します。
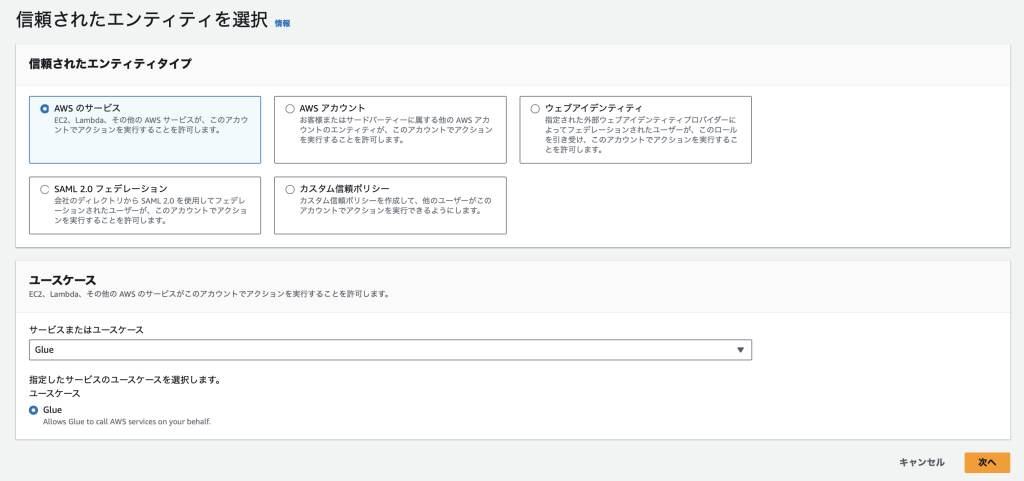
今回のスクリプトではS3にアクセスするので、S3への操作の許可も追加します。

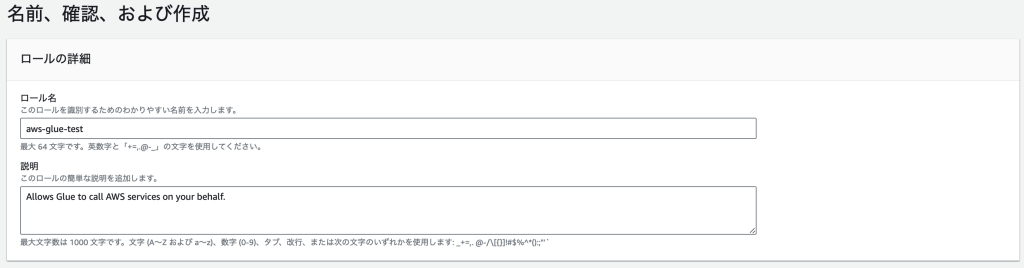
ロール名を入力し、設定内容に問題なければ「ロールを作成」ボタンをクリック。
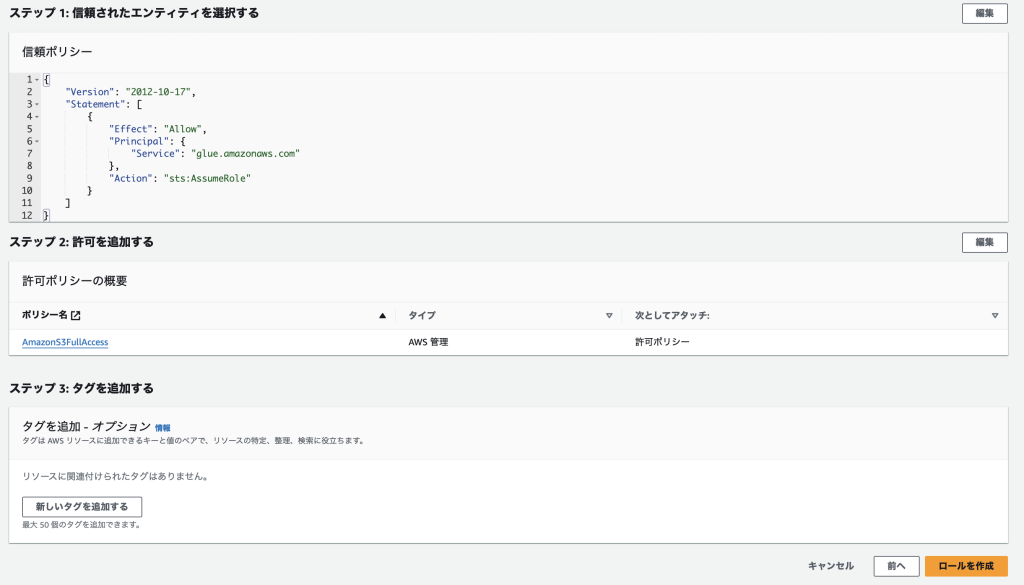
以上でIAMロールの作成が完了です。
S3バケットの作成
今回の検証用のファイルを格納しておくS3バケットを作成しておきます。
設定は全てデフォルトで作成します。
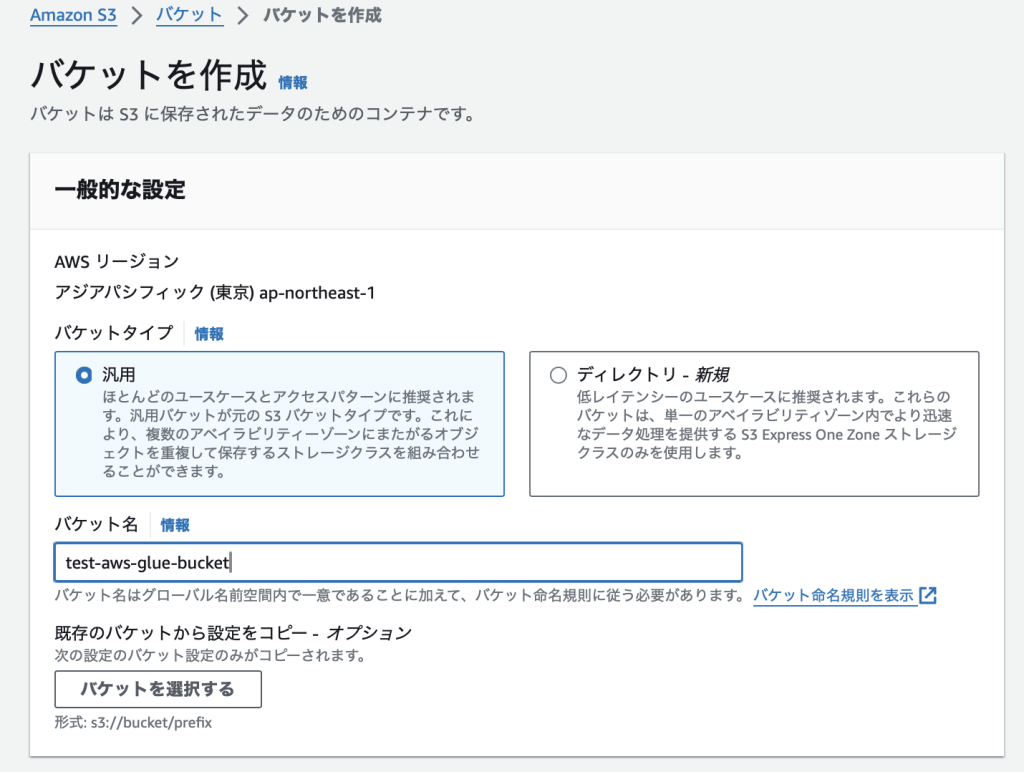
以上でS3バケットの作成は完了です。
AWS Glueスクリプトの作成
AWS Glueで実行するスクリプトを作成していきます。
マネジメントコンソール上でAWS Glueのサービスに移動し、「Visual ETL」をクリックします。
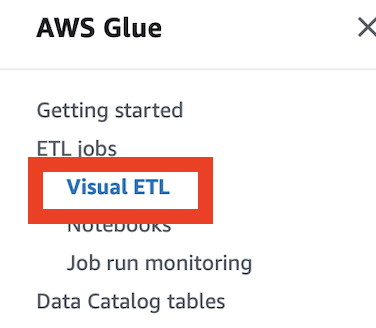
次に「Script Editor」をクリックします。
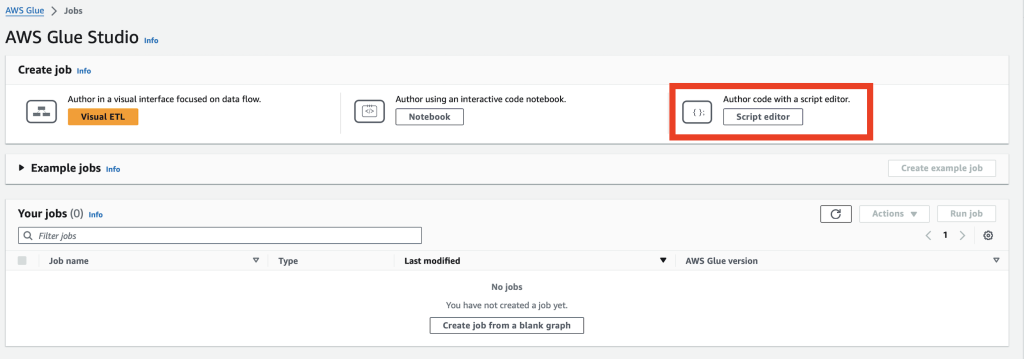
「Engin」に「Spark」を選択し、「Create script」をクリック。
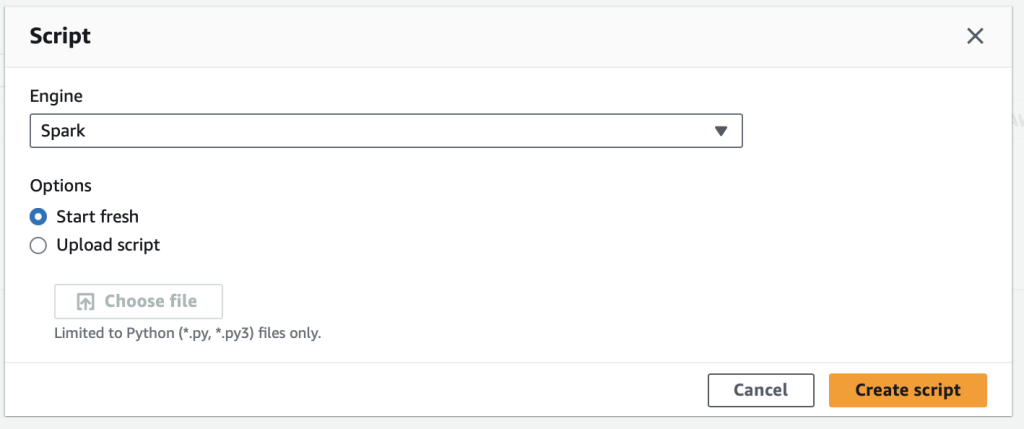
クリック後、以下のようにスクリプトを記述するエディタが表示されます。AWS GlueのスクリプトはPythonで記述します。
デフォルトでは上記のようになっているので、今回実行するファイルを統合する処理に変更します。
変更したスクリプト全体はこちらです。
import sys
from awsglue.context import GlueContext
from awsglue.job import Job
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from pyspark.sql import SparkSession
from pyspark.sql.functions import input_file_name
# 引数の取得
args = getResolvedOptions(sys.argv, ['JOB_NAME', 'S3_SOURCE_PATH', 'S3_DEST_PATH'])
# コンテキストとジョブの初期化
sc = SparkContext()
glueContext = GlueContext(sc)
spark = SparkSession.builder.getOrCreate()
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
# S3のソースパスからデータを読み込む
# ブックマークオプションを追加
dynamic_frame = glueContext.create_dynamic_frame.from_options(
connection_type="s3",
connection_options={
"paths": [args['S3_SOURCE_PATH']],
"recurse": True
},
format="csv",
transformation_ctx="s3_source_path_transformation_ctx" # ブックマーク用のtransformation_ctxを指定
)
# DataFrameに変換
data_frame = dynamic_frame.toDF()
# データを統合する
consolidated_df = data_frame.coalesce(1)
# 統合したデータをS3の目的のパスに書き込む
consolidated_df.write.mode("overwrite").format("csv").save(args['S3_DEST_PATH'])
# ジョブの終了
job.commit()順番に解説していきます。
ポイント1:パラメータの受け取り
以下のコードで、操作するS3バケットの情報を外部から受け取ります。
# 引数の取得
args = getResolvedOptions(sys.argv, ['JOB_NAME', 'S3_SOURCE_PATH', 'S3_DEST_PATH'])ここで受け取るパラメータは「job details」タブから設定することができます。
設定手順は、スクリプト作成完了後に解説します。
ポイント2:分散処理を行うDynamicFrameworkを利用
以下のコードで、データソースからの読み込みをしています。
# S3のソースパスからデータを読み込む
# ブックマークオプションを追加
dynamic_frame = glueContext.create_dynamic_frame.from_options(
connection_type="s3",
connection_options={
"paths": [args['S3_SOURCE_PATH']],
"recurse": True
},
format="csv",
transformation_ctx="s3_source_path_transformation_ctx" # ブックマーク用のtransformation_ctxを指定
)
# DataFrameに変換
data_frame = dynamic_frame.toDF()AWS Glueが提供しているDynamicFrameworkという機能を利用することで分散処理が実現されています。
AWS GlueではS3上のファイルを直接読み込むため、対象ファイルをダウンロードしない分高速に処理します。
ポイント3:ブックマーク機能の利用
DynamicFrameのオプションで「transformation_ctx」を指定することで、ブックマーク機能が利用できます。
transformation_ctx="s3_source_path_transformation_ctx"指定する値は任意の名称を設定します。この名称を元に前回実行分のポインタを参照し差分処理を実現しています。
分散処理を行うには以下のどちらかの機能を利用します。
- Apache Spark
- DynamicFramework
今回はブックマーク機能が利用できるDynamicFrameworkを利用しています。
DynamicFrameworkも内部的にApache Sparkを利用しているため、分散処理のコアな処理方式は同じです。
ジョブの詳細情報の設定
ジョブの名称と実行するIAMロールを設定します。
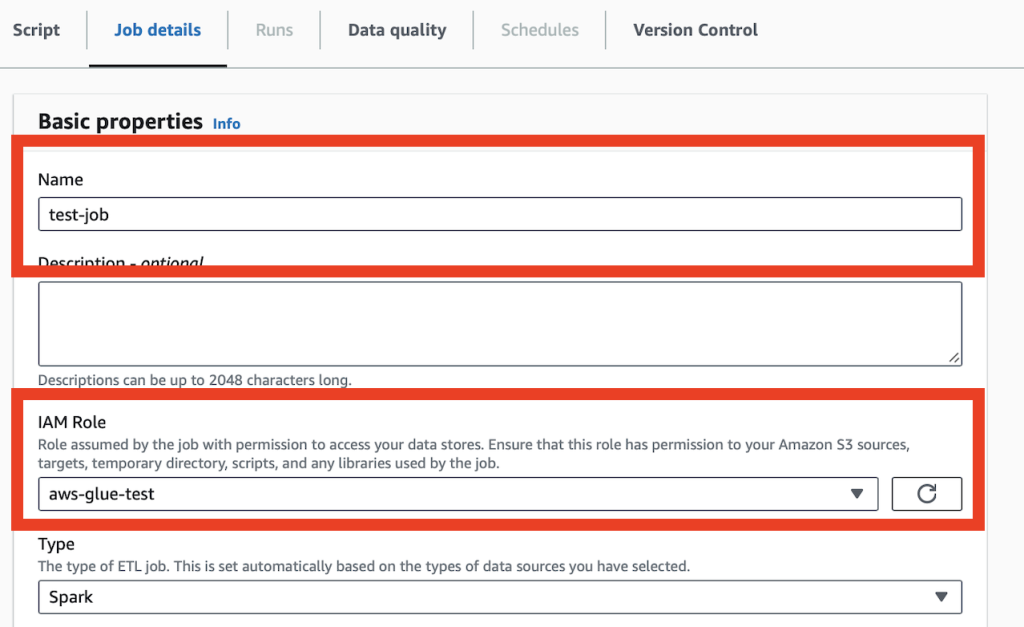
ブックマーク機能を有効にするには、「job bokmark」を「Enable」に設定します。

ジョブパラメータに以下を設定します。
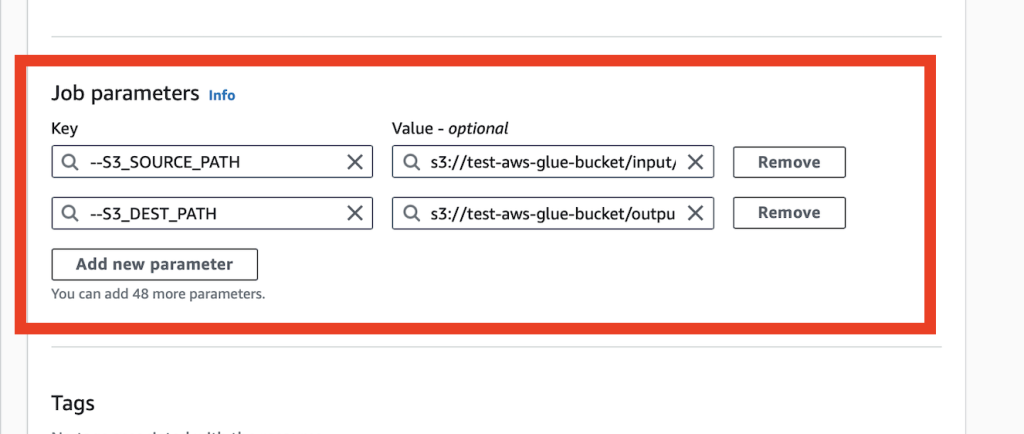
今回はファイルの入力を「input」フォルダ、統合したファイルの出力先を 「output」に設定してます。
| Key | Value |
|---|---|
| –S3_DEST_PATH | s3://test-aws-glue-bucket/input/ |
| –S3_SOURCE_PATH | s3://test-aws-glue-bucket/output/ |
設定が終わったら、右上にある「Save」ボタンをクリックします。
スクリプトの実行
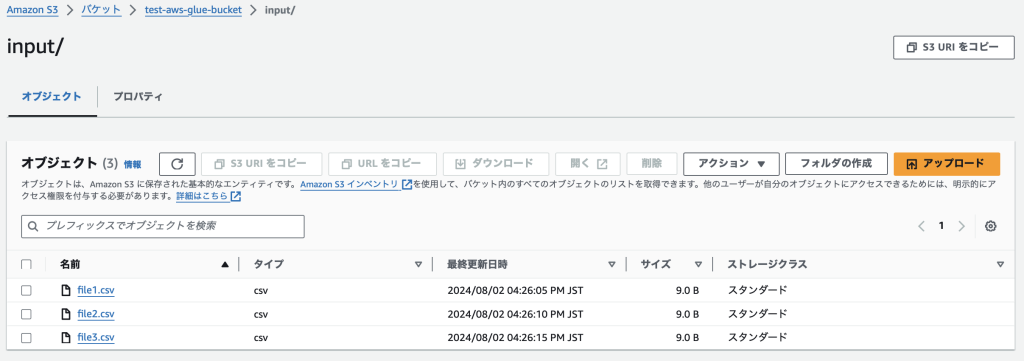
スクリプトを実行してみます。
テスト用にS3のinputフォルダに9Bのファイルを3つ格納しておきます。
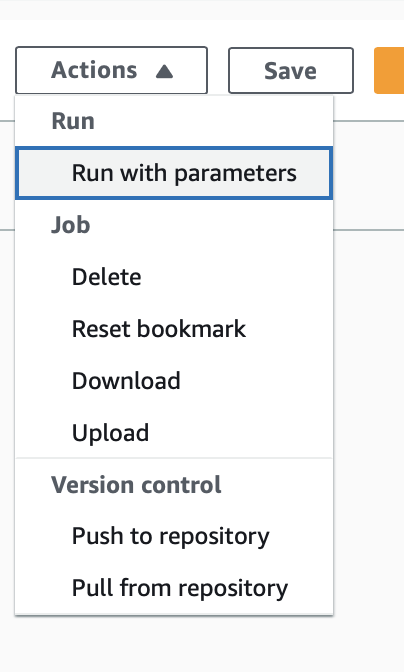
AWSGlueの右上のActionsから「Run with parameters」を選択しスクリプトを実行します。
以下の確認メッセージでは「Run job」をクリックします。
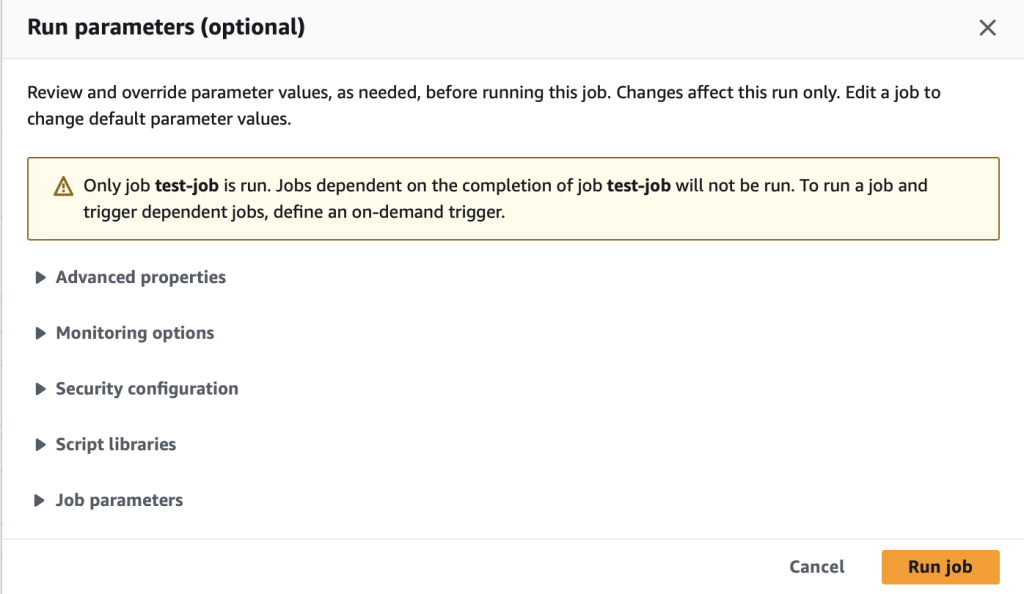
「Runs」タブで実行状況を確認できます。「Succeeded」となれば処理が正常終了してます。
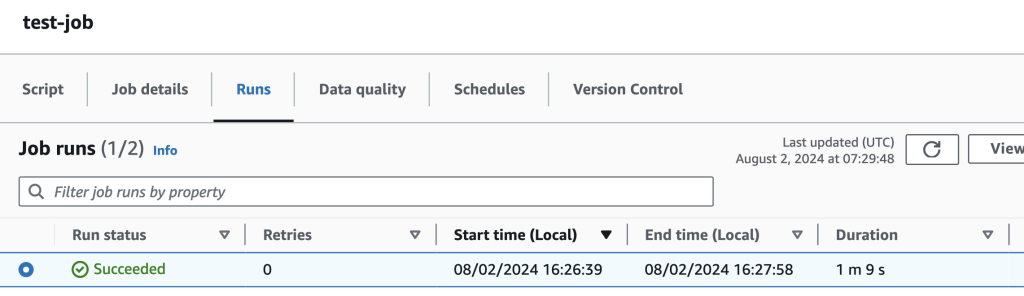
S3のoutputフォルダを見ると、33Bのファイルが一つ作成されています。
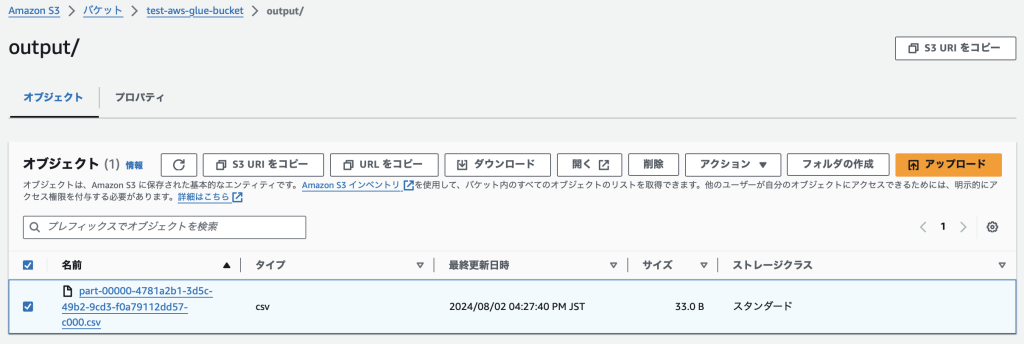
スクリプトの性能はWorker Typeで向上できます。
まとめ
この記事のまとめです。
- AWS Glueは分散処理を簡単に実行できる
- ブックマーク機能で差分データの処理をプログラムの作成なしで実現可能
- 対象データ量に応じて、性能を適切に設定可能
AWS Glueを利用することで分散処理を簡単に実現できました。
AWS Glueを使わずに分散処理を実現しようとすると、かなりの労力がかかるため、このように簡単に実現できるのは助かります。
分散処理を適用できる場面は、本記事のように単純な処理を大量データに対して実行しなければならない場面と限定的ですが、利用できればパフォーマンスが大幅に改善されます。
また、Glueを実行するインスタンスのスペックを変更することができるため、処理に応じて適切なスペックに設定することが可能です。
本記事が皆様の参考になれば幸いです。

コメント